A robots.txt file is a text file that guides search engine crawlers on which pages to crawl or avoid. It helps control indexing, manage the crawl budget, and prevent unnecessary bot traffic on specific website sections.
Robots.txt Generator
Create and Customize a Robots.txt File For Your Website!
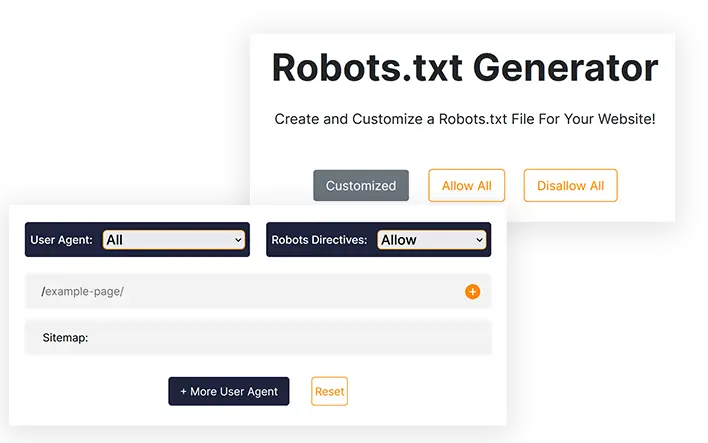
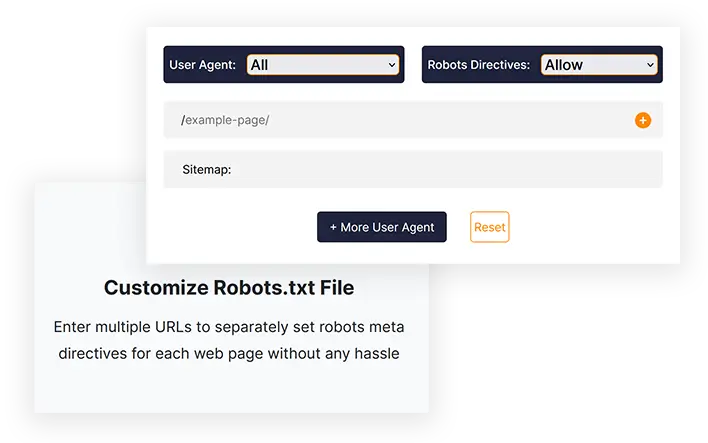
User Agent:
Robots Directives:
/
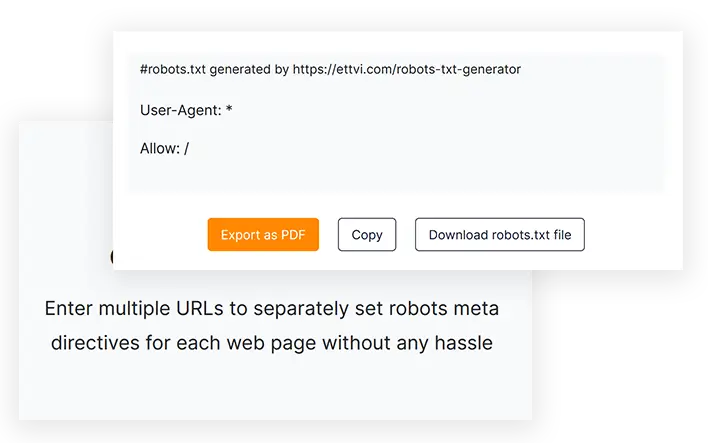
#robots.txt generated by https://ettvi.com/robots-txt-generator
User-Agent: *
Allow: /
| Customized |
|---|
| Allow |
|---|
| Disallow |
|---|
Features

Generate Robots.txt File
Create a robots.txt file for your website or web pages to specify crawl instructions without any coding error

Customize Robots.txt File
Enter multiple URLs to separately set robots meta directives for each web page without any hassle

One-click Export
Copy the robots.txt code or directly download the robots.txt file to upload in your website root directory
Related Tools
ETTVI’s Robots.txt Generator
Create Robots.txt file for your website to determine the behavior of search engine crawlers with ETTVI's Robots.txt Generator. The webmasters can leverage this tool to generate a standard Robots.txt file with default settings or customize it to set specific crawl instructions for different web pages.
Take advantage of the advanced-level functionalities of ETTVI's Robots.txt Generator to restrict a directory from crawling or hide your private pages from the crawler.
Separetely include robots meta directives for each URL to indicate what and how the crawlers can access the respective links without wasting your crawl budget. Allow or disallow different search engine crawlers from crawling your web content just as required.
ETTVI's Robots.txt Creator effectively processes the given information to specify the crawl instructions without any coding error. Inform the crawlers about how they should crawl and index your web pages with ETTVI's Robots.txt Generator for free of cost.
How to Use ETTVI’s Robots.txt Generator?
ETTVI’s Robots.txt Generator enables the users to generate a default Robots.txt file with “All Allow” or “All Disallow” crawl instructions as well as create a custom Robots.txt file with additional functionalities.
Generate a Standard Robots.txt File
Follow these steps to generate a standard Robots.txt file with default settings:
STEP 1 - Set Robots Meta Directives
You can set allow/disallow directives for “all search engine robots” to generate a standard robots.txt file. Choose “Allow” or “Disallow” to apply the default settings:
STEP 2 - Enter Sitemap Address
Enter the link to your website’s sitemap or leave it blank if you don’t have any.
You can enter more than one category-specific sitemaps of your website pages, posts, categories, and tags.
STEP 3 - Get Robots.txt Code
Just as you enter the required information, ETTVI’s Robots.txt Generator automatically generates and displays the Robots.txt code.
You can download or copy the code to submit the Robots.txt file to your website’s root directory.
Generate Custotmized Robots.txt File
Follow these steps to generate a standard Robots.txt file with default settings:
Enter URLs:
STEP 2 - Select User Agent
You can set meta robots directives for any of the following user agents:
- Google Image
- Google Mobile
- MSN Search
- Yahoo
- Yahoo MM
- Yahoo Blogs
- Baidu
- MSN PicSearch
You can select different user agents for different URLs.
STEP 3 - Allow/Disallow Search Engine Robots
Select “Allow or Disallow” to set the robots meta directives for the given URLs.
You can separately set “Allow” or “Disallow” directive for each URL.
Why Use ETTVI's Robots.txt Generator?
Robots.txt is a file that is used to give instructions to search engine’s crawler to about which urls can be crawled or indexed or which shouldn’t . The robots.txt is very crucial and beneficial for webmasters and every SEO expert uses robots.txt for different purposes.
However, if not written properly, it can cause indexing problems in your site and Google can’t crawl your website properly. Using ETTVI's Robots.txt creator, you can generate an accurate file rather than manually coding in just a single click.
Quickly Create Robots.txt File
Robots.txt Generator can save you from any coding error and it saves a lot of time that you can apply on other SEO Tasks like Generating sitemap. Most SEO experts recommend ETTVI's Robots.txt Generator because it is an efficient, fast and free tool that will make your robots.txt in no time according to your needs.
Hide Private Pages
Suppose if you have a private page that you only want to show that to subscribed people but if it gets indexed everyone can see it - So, to avoid this problem you need to disallow your private pages in robots.txt.
Save Crawl Budget
If you have a lot of extra pages (Like Tags) then they can disturb your crawl budget and cause indexing problems. So, we disallow extra pages in robots.txt to avoid this problem.

Understanding Robots.txt?
The Robots.txt file is a text file that contains information about how a crawler should crawl a website. In addition, you can specify what areas you do not want to allow the crawlers to access, for example, areas with duplicate content or those under construction. There are some bots that do not follow this standard, including malware detectors and email harvesters. As a result, they will search for weak points in your security system. If you do not wish to have certain areas indexed, there is a reasonable chance that they will begin to review your website from those areas.
There are typically two Robots.txt files: one provides the "User-agent" and the other includes directives which are ‘Allow,’ ‘Disallow,’ ‘Crawl-Delay,’ etc. Manually writing a file of command lines might take quite a long time, and the file can contain multiple lines of commands at one time. You should write "Disallow: the link you do not wish to have bots visit" on the following page. The same method applies for the "allowing" command.
Why Is Robots.txt Important?
Robots.txt files are not required by most websites. As a result, Google is often able to find all the important pages of your website, and index them, without any difficulty. And they will not index pages that aren't of importance or duplicates of pages already indexed.
However, there are three main reasons for using a robots.txt file.
Don't allow Non-Public pages to be seen. Sometimes, you do not want certain pages indexed on your site. You might, for instance, have staging versions of certain pages or a login page. It is imperative that these pages exist and andom users should not be directed to them. So, the robots.txt should be used to block crawlers and bots from accessing these pages.
Make the most of your crawl budget. There might be a crawl budget problem if you are having difficulty getting your pages indexed. When you use robots.txt to block unimportant pages, Googlebot will spend more time on the web pages that are actually important.
Resources should not be indexed. You can use meta directives to prevent a page from being indexed just as efficiently as using a Robot.txt file. Meta directives, however, do not function well with multimedia resources such as PDFs and images. In this case, robots.txt would be useful.
When search engine bots examine files, they are first looking for the robots.txt file, and if this file isn't found, there is a significant chance that all of your site's pages won't be indexed. When you add more pages, you can modify the Robot.txt file with a few instructions by adding the main page to the disallow list. However, avoid adding the main page to the disallow list at the beginning of the file.
There is a budget for crawling Google's website; this budget is determined by a crawl limit. As a rule, crawlers will spend a certain amount of time on a website before moving on to the next one, but if Google discovers that crawling your site is disturbing your users, it will crawl your site more slowly. Due to Google's slower spidering of your website, it will only index a few pages of your site at a time, so your most recent posting will take time to fully index. It is necessary that your site has a sitemap and a robots.txt file in order to fix this problem. The crawling process will be made faster by directing them to the links of your site that require special attention in order to speed up the process of crawling.
In addition to having a crawl rate for a website, each bot has its own unique crawl quote. That is why you need a robot file for your WordPress website. This is due to the fact that it consists of a great deal of pages that are not needed for indexing. Furthermore, if you choose not to include a robots.txt file, crawlers will still index your website, but unless it's a very large blog and contains lots of pages, it is not necessary.
The Purpose of Directives in a Robot.txt File:
When creating the manual file, it is imperative that you are aware of how the file should be formatted. Additionally, after learning how it works, you can modify it.
Crawl-time delay: By setting this directive, crawlers will not overload the server, since too many requests will make the server overworked, not resulting in an optimal user experience. Different search engine bots respond differently to the Crawl-Delay directive. For instance, Bing, Google, and Yandex all respond differently.
Allowing: By using this directive, we allow the following URLs to be indexed. Regardless of the number of URLs you may add to your list, if you are running an E-commerce website, you might have a lot of URLs to add. If you do decide to use the robots file, then you should only use it for the pages which you don't want to be indexed.
Disallowing: Among the most important functions of a Robots file is to prevent crawlers from being able to access links, directories, etc. within it. However, other bots can access these directories, which means they have to check for malware because they aren't compliant.
Difference Between a Sitemap and a Robot.txt file
A sitemap contains valuable information for search engines and is essential for all websites. Sitemaps inform bots when your website is updated as well as what type of content your website offers. The purpose of the page is to inform the search engine of all the pages your site contains that should be crawled, while the purpose of the robots.txt file is to notify the crawler. Crawlers are told what pages to crawl and which to avoid using Robot.txt. For your website to be indexed, you will need a sitemap, whereas robot.txt is not required.
Frequently Ask Questions
What Is a Robots.txt File?
Advertisement
What is Robots.txt Generator?
Robots.txt Generator is an online web-based tool that allows webmasters to create customized robots.txt according to their needs without any manual coding.
Is Robots.txt Necessary?
No, a robots.txt is not necessary but with it you can have control over search engines’ crawlers. Most experts recommend having a robots.txt file on your website.
How Do I Create a Robots.txt File?
You can create one with manual coding but it is too dangerous and can cause indexing problems. So, the best solution to save from this problem is to use a Robots.txt Generator like Ettvi’s. Ettvi’s Robots.txt Generator allows you to create your own customized file free.
Advertisement
How to Validate if My Robots.txt is Good or not?
After generating and placing Robots.txt it's a major question how to validate robots.txt file? You can easily validate your file with ETTVI’s Robots.txt Validator Tool.
Do We Still Use Robots.txt?
Yes, robots.txt is still used to manage search engine crawlers efficiently. It prevents unnecessary crawling, protects private directories, and optimizes website performance by guiding bots to prioritize important content.

Stay up to date in the email world.
Subscribe for weekly emails with curated articles, guides, and videos to enhance your tactics.
