robots.txt はルート ディレクトリに配置されるファイルです。検索エンジンのクローラーにサイトのクロールとインデックス作成に関する指示を与えるために使用されます。使用方法によっては、有益な場合もあれば危険な場合もあります。
Robots.txt ジェネレーター
ウェブサイト用の robots.txt ファイルを作成してカスタマイズしましょう。
User Agent:
Robots Directives:
/
https://ettvi.com/robots-txt-generator によって生成された #robots.txt
User-Agent: *
Allow: /
| Customized |
|---|
| Allow |
|---|
| Disallow |
|---|
特徴

Robots.txt ファイルを生成する
ウェブサイトまたはウェブページ用のrobots.txtファイルを作成し、コーディングエラーなしでクロールの指示を指定します。

Robots.txt ファイルをカスタマイズする
複数のURLを入力して、各Webページのrobotsメタディレクティブを個別に設定できます。

ワンクリックエクスポート
robots.txtコードをコピーするか、robots.txtファイルを直接ダウンロードして、ウェブサイトのルートディレクトリにアップロードします。
ETTVI の Robots.txt ジェネレーター
ETTVI の Robots.txt ジェネレーターを使用して、Web サイトの Robots.txt ファイルを作成し、検索エンジン クローラーの動作を決定します。Web マスターはこのツールを利用して、デフォルト設定で標準の Robots.txt ファイルを生成したり、さまざまな Web ページに特定のクロール指示を設定するようにカスタマイズしたりできます。
ETTVI の Robots.txt ジェネレーターの高度な機能を活用して、ディレクトリのクロール制限や、クローラーからプライベート ページを非表示にすることができます。
各 URL に robots メタ ディレクティブを個別に含めて、クロール バジェットを無駄にすることなく、クローラーがそれぞれのリンクに何をどのようにアクセスできるかを指定します。必要に応じて、さまざまな検索エンジン クローラーによる Web コンテンツのクロールを許可または禁止します。
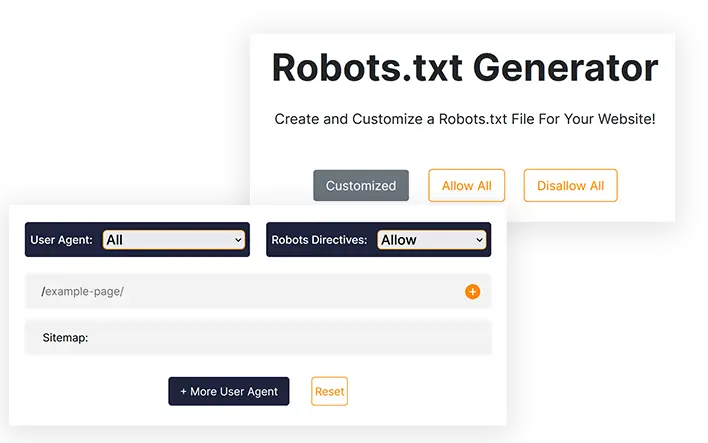
ETTVI の Robots.txt ジェネレーターの使い方
ETTVI の Robots.txt ジェネレーターを使用すると、ユーザーは「すべて許可」または「すべて不許可」のクロール指示を含むデフォルトの Robots.txt ファイルを生成できるほか、追加機能を備えたカスタム Robots.txt ファイルを作成することもできます。
標準のRobots.txtファイルを生成する
デフォルト設定で標準の Robots.txt ファイルを生成するには、次の手順に従います。
ステップ 1 - ロボットのメタディレクティブを設定する
「すべての検索エンジン ロボット」に対して許可/不許可のディレクティブを設定して、標準の robots.txt ファイルを生成することができます。デフォルト設定を適用するには、「許可」または「不許可」を選択します。
ステップ2 - サイトマップアドレスを入力する
ウェブサイトのサイトマップへのリンクを入力するか、サイトマップがない場合は空白のままにします。
ウェブサイトのページ、投稿、カテゴリ、タグのカテゴリ固有のサイトマップを複数入力できます。
ステップ3 - Robots.txtコードを取得する
必要な情報を入力すると、ETTVI の Robots.txt ジェネレーターが自動的に Robots.txt コードを生成して表示します。
コードをダウンロードまたはコピーして、Robots.txt ファイルを Web サイトのルート ディレクトリに送信できます。
カスタマイズされた Robots.txt ファイルを生成する
デフォルト設定で標準の Robots.txt ファイルを生成するには、次の手順に従います。
URLを入力してください:
ステップ2 - ユーザーエージェントの選択
次のいずれかのユーザー エージェントに対してメタ ロボット ディレクティブを設定できます。
- グーグル
- Googleの画像
- Google モバイル
- MSN検索
- ヤフー
- ヤフーMM
- ヤフーブログ
- 百度
- MSN PicSearch
異なる URL に対して異なるユーザー エージェントを選択できます。
ステップ 3 - 検索エンジンロボットを許可/禁止する
指定された URL の robots メタ ディレクティブを設定するには、「許可または不許可」を選択します。
各 URL に対して「許可」または「許可しない」ディレクティブを個別に設定できます。
ETTVI の Robots.txt ジェネレーターを使用する理由
robots.txt は、どの URL をクロールまたはインデックス化できるか、またどの URL をクロールまたはインデックス化すべきでないかに関して検索エンジンのクローラーに指示を与えるために使用されるファイルです。robots.txt はウェブマスターにとって非常に重要かつ有益であり、すべての SEO 専門家がさまざまな目的で robots.txt を使用しています。
ただし、適切に記述しないと、サイトのインデックス作成に問題が発生し、Google が Web サイトを適切にクロールできなくなります。ETTVI の Robots.txt ジェネレーターを使用すると、手動でコーディングする代わりに、クリック 1 回で正確なファイルを生成できます。
Robots.txt ファイルを素早く作成する
Robots.txt ジェネレーターは、コーディング エラーを回避し、サイトマップの生成などの他の SEO タスクに充てる時間を大幅に節約します。ほとんどの SEO 専門家は、ETTVI の Robots.txt ジェネレーターを推奨しています。これは、ニーズに応じて robots.txt をすぐに作成できる効率的で高速な無料ツールだからです。
プライベートページを非表示にする
登録した人だけに表示したいプライベート ページがあるが、インデックスされると誰でも閲覧可能になる場合、この問題を回避するには、robots.txt でプライベート ページを禁止する必要があります。
クロールバジェットを節約
余分なページ(タグなど)がたくさんあると、クロール バジェットが妨げられ、インデックス作成の問題が発生する可能性があります。そのため、この問題を回避するために、robots.txt で余分なページを許可しません。

Robots.txt を理解していますか?
Robots.txt ファイルは、クローラーが Web サイトをクロールする方法に関する情報を含むテキスト ファイルです。さらに、重複コンテンツのある領域や構築中の領域など、クローラーがアクセスできないようにする領域を指定することもできます。マルウェア検出機能やメール収集機能など、この標準に従わないボットも存在します。その結果、ボットはセキュリティ システムの弱点を探します。特定の領域をインデックスに登録したくない場合は、ボットがそれらの領域から Web サイトをレビューし始める可能性が高くなります。
通常、Robots.txt ファイルは 2 つあります。1 つは「User-agent」を提供し、もう 1 つは「Allow」、「Disallow」、「Crawl-Delay」などのディレクティブを含みます。コマンド ラインのファイルを手動で記述すると、かなり時間がかかる場合があります。また、ファイルには一度に複数のコマンド行が含まれる場合があります。次のページに「Disallow: ボットがアクセスしないようにするリンク」と記述する必要があります。「allowing」コマンドにも同じ方法が適用されます。
Robots.txt が重要な理由
ほとんどのウェブサイトでは、robots.txt ファイルは必要ありません。その結果、Google は多くの場合、ウェブサイトの重要なページをすべて簡単に見つけてインデックスすることができます。また、重要でないページや、すでにインデックスされているページの重複はインデックスされません。
ただし、robots.txt ファイルを使用する主な理由は 3 つあります。
非公開ページを表示しないようにします。場合によっては、サイト上の特定のページをインデックスに登録したくないことがあります。たとえば、特定のページのステージング バージョンやログイン ページがある場合があります。これらのページは必ず存在し、不特定多数のユーザーがそれらのページに誘導されないようにする必要があります。そのため、robots.txt を使用して、クローラーやボットがこれらのページにアクセスするのをブロックする必要があります。
クロール バジェットを最大限に活用します。ページのインデックス作成に問題がある場合は、クロール バジェットの問題がある可能性があります。robots.txt を使用して重要でないページをブロックすると、Googlebot は実際に重要な Web ページに多くの時間を費やすようになります。
リソースはインデックス化されるべきではありません。メタ ディレクティブを使用すると、Robot.txt ファイルを使用するのと同じくらい効率的に、ページがインデックス化されないようにすることができます。ただし、メタ ディレクティブは、PDF や画像などのマルチメディア リソースではうまく機能しません。この場合は、robots.txt が役立ちます。
検索エンジン ボットがファイルを調べるとき、最初に robots.txt ファイルを探します。このファイルが見つからない場合、サイトのすべてのページがインデックスに登録されない可能性が高くなります。ページを追加する場合は、いくつかの指示に従って Robot.txt ファイルを変更し、メイン ページを不許可リストに追加することができます。ただし、ファイルの先頭でメイン ページを不許可リストに追加することは避けてください。
Google のウェブサイトをクロールするための予算があり、この予算はクロール制限によって決定されます。通常、クローラーは、次のウェブサイトに移動する前に、ウェブサイトに一定の時間を費やしますが、Google は、サイトのクロールがユーザーの邪魔になっていると判断した場合、サイトのクロール速度を遅くします。Google のウェブサイトのスパイダー速度が遅いため、一度にインデックスされるのはサイトの数ページのみであるため、最新の投稿が完全にインデックスされるまでに時間がかかります。この問題を解決するには、サイトにサイトマップと robots.txt ファイルが必要です。クロール プロセスを高速化するには、クロール プロセスを特別な注意を必要とするサイトのリンクに誘導します。
ウェブサイトのクロール レートに加えて、各ボットには独自のクロール クォートがあります。WordPress ウェブサイトにロボット ファイルが必要なのはそのためです。これは、インデックス作成に不要なページが多数含まれているためです。さらに、robots.txt ファイルを含めないことを選択した場合でも、クローラーはウェブサイトをインデックスしますが、非常に大きなブログで多数のページが含まれていない限り、このファイルは必要ありません。
Robot.txt ファイル内のディレクティブの目的:
マニュアル ファイルを作成するときは、ファイルがどのようにフォーマットされるかを知っておくことが不可欠です。また、その動作を学んだ後、ファイルを変更できます。
クロール時間遅延: このディレクティブを設定すると、クローラーがサーバーに過負荷をかけなくなります。リクエストが多すぎるとサーバーが過負荷になり、最適なユーザー エクスペリエンスが得られなくなるためです。検索エンジン ボットによって、クロール時間遅延ディレクティブに対する応答は異なります。たとえば、Bing、Google、Yandex はすべて応答が異なります。
許可: このディレクティブを使用すると、次の URL のインデックス作成が許可されます。リストに追加する URL の数に関係なく、電子商取引 Web サイトを運営している場合は、追加する URL が多数ある可能性があります。robots ファイルを使用する場合は、インデックス作成を希望しないページにのみ使用してください。
不許可: Robots ファイルの最も重要な機能の 1 つは、クローラーがファイル内のリンクやディレクトリなどにアクセスできないようにすることです。ただし、他のボットはこれらのディレクトリにアクセスできるため、準拠していないためマルウェアのチェックが必要になります。
サイトマップと Robot.txt ファイルの違い
サイトマップには検索エンジンにとって貴重な情報が含まれており、すべてのウェブサイトに不可欠です。サイトマップは、ウェブサイトが更新された時期やウェブサイトが提供するコンテンツの種類をボットに通知します。ページの目的は、サイトに含まれるクロールすべきすべてのページを検索エンジンに通知することです。一方、robots.txt ファイルの目的は、クローラーに通知することです。クローラーは、Robot.txt を使用して、クロールするページと回避するページを指示されます。ウェブサイトをインデックスするには、サイトマップが必要ですが、robot.txt は必須ではありません。
よくある質問
Robots.txt ファイルとは何ですか?
Advertisement
Robots.txt ジェネレーターとは何ですか?
Robots.txt ジェネレーターは、ウェブマスターが手動でコーディングすることなく、ニーズに応じてカスタマイズされた robots.txt を作成できるオンライン ウェブ ベースのツールです。
Robots.txt は必要ですか?
いいえ、robots.txt は必須ではありませんが、これを使用すると検索エンジンのクローラーを制御できます。ほとんどの専門家は、Web サイトに robots.txt ファイルを置くことを推奨しています。
Robots.txt ファイルを作成するにはどうすればよいですか?
手動コーディングで作成することもできますが、非常に危険であり、インデックス作成の問題を引き起こす可能性があります。したがって、この問題を回避するための最善の解決策は、Ettvi のような Robots.txt ジェネレータを使用することです。Ettvi の Robots.txt ジェネレータを使用すると、独自のカスタマイズされたファイルを無料で作成できます。
Advertisement
Robots.txt が適切かどうかを検証するにはどうすればいいですか?
Robots.txt を生成して配置した後、robots.txt ファイルをどのように検証するかが大きな問題になります。ETTVI の Robots.txt 検証ツールを使用すると、ファイルを簡単に検証できます。

メールの世界で最新情報を入手してください。
厳選された記事、ガイド、ビデオが掲載された毎週のメールを購読して、戦術を強化してください。
