Robots.txt ist eine Datei, die im Stammverzeichnis abgelegt wird. Sie wird verwendet, um dem Crawler der Suchmaschine Anweisungen zum Crawlen und Indexieren der Site zu geben . Je nach Verwendung kann dies nützlich oder gefährlich sein.
Robots.txt-Generator
Erstellen und passen Sie eine Robots.txt-Datei für Ihre Website an!
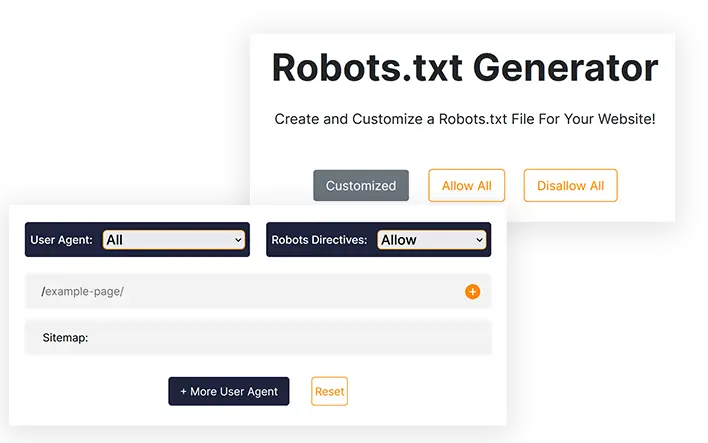
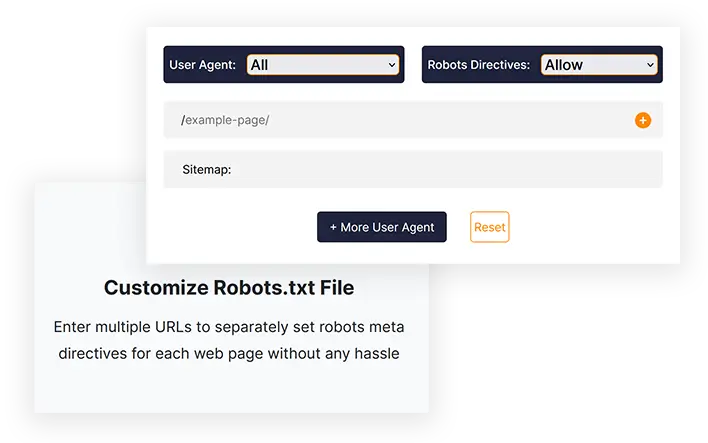
User Agent:
Robots Directives:
/
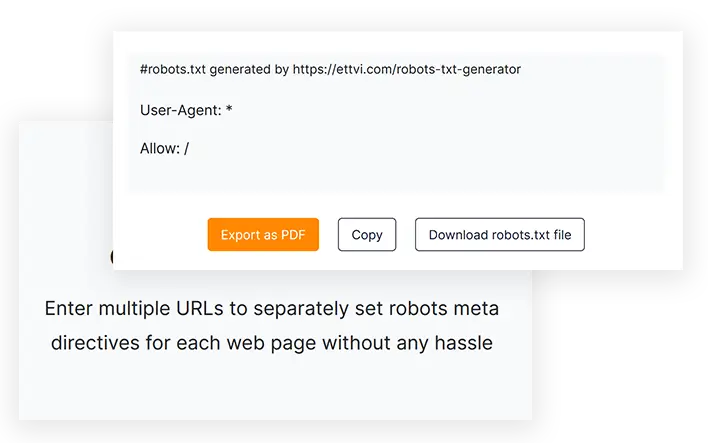
#robots.txt generiert von https://ettvi.com/robots-txt-generator
User-Agent: *
Allow: /
| Customized |
|---|
| Allow |
|---|
| Disallow |
|---|
Merkmale

Robots.txt-Datei generieren
Erstellen Sie eine robots.txt-Datei für Ihre Website oder Webseiten, um Crawl-Anweisungen ohne Codierungsfehler anzugeben

Robots.txt-Datei anpassen
Geben Sie mehrere URLs ein, um die Robots-Meta-Direktiven für jede Webseite ohne großen Aufwand separat festzulegen

Export mit einem Klick
Kopieren Sie den robots.txt-Code oder laden Sie die robots.txt-Datei direkt herunter, um sie in das Stammverzeichnis Ihrer Website hochzuladen
Gerelateerde hulpmiddelen
ETTVIs Robots.txt-Generator
Erstellen Sie mit dem Robots.txt-Generator von ETTVI eine Robots.txt-Datei für Ihre Website, um das Verhalten von Suchmaschinen-Crawlern zu ermitteln . Die Webmaster können dieses Tool nutzen, um eine standardmäßige Robots.txt-Datei mit Standardeinstellungen zu generieren oder sie anzupassen, um spezifische Crawling-Anweisungen für verschiedene Webseiten festzulegen.
Nutzen Sie die erweiterten Funktionen des Robots.txt-Generators von ETTVI, um das Crawlen eines Verzeichnisses einzuschränken oder Ihre privaten Seiten vor dem Crawler zu verbergen.
Fügen Sie für jede URL separate Robots-Metaanweisungen ein, um anzugeben, was und wie die Crawler auf die jeweiligen Links zugreifen können, ohne Ihr Crawl-Budget zu verschwenden. Erlauben oder untersagen Sie je nach Bedarf das Crawlen Ihrer Webinhalte durch verschiedene Suchmaschinen-Crawler.
Der Robots.txt Creator von ETTVI verarbeitet die gegebenen Informationen effektiv, um die Crawl-Anweisungen ohne Codierungsfehler festzulegen. Informieren Sie die Crawler mit dem kostenlosen Robots.txt Generator von ETTVI darüber, wie sie Ihre Webseiten crawlen und indexieren sollen.
Wie verwende ich den Robots.txt-Generator von ETTVI?
Mit dem Robots.txt-Generator von ETTVI können Benutzer eine standardmäßige Robots.txt-Datei mit den Crawling-Anweisungen „Alle zulassen“ oder „Alle nicht zulassen“ generieren sowie eine benutzerdefinierte Robots.txt-Datei mit zusätzlichen Funktionen erstellen.
Generieren Sie eine Standard-Robots.txt-Datei
Befolgen Sie diese Schritte, um eine standardmäßige Robots.txt-Datei mit Standardeinstellungen zu generieren:
SCHRITT 1 - Robots-Metadirektiven festlegen
Sie können für „alle Suchmaschinen-Robots“ Allow/Disallow-Anweisungen festlegen, um eine standardmäßige robots.txt-Datei zu generieren. Wählen Sie „Allow“ oder „Disallow“, um die Standardeinstellungen anzuwenden:
SCHRITT 2 - Sitemap-Adresse eingeben
Geben Sie den Link zur Sitemap Ihrer Website ein oder lassen Sie das Feld leer, wenn Sie keine haben.
Sie können mehrere kategoriespezifische Sitemaps der Seiten, Beiträge, Kategorien und Tags Ihrer Website eingeben.
SCHRITT 3 – Robots.txt-Code abrufen
Sobald Sie die erforderlichen Informationen eingeben, generiert der Robots.txt-Generator von ETTVI automatisch den Robots.txt-Code und zeigt ihn an.
Sie können den Code herunterladen oder kopieren, um die Datei Robots.txt an das Stammverzeichnis Ihrer Website zu senden.
Benutzerdefinierte Robots.txt-Datei generieren
Befolgen Sie diese Schritte, um eine standardmäßige Robots.txt-Datei mit Standardeinstellungen zu generieren:
Geben Sie URLs ein:
SCHRITT 2 - User Agent auswählen
Sie können Meta-Robots-Direktiven für jeden der folgenden Benutzeragenten festlegen:
- Google Bild
- Google Mobile
- MSN Suche
- Yahoo
- Yahoo MM
- Yahoo Blogs
- Baidu
- MSN PicSearch
Sie können für unterschiedliche URLs unterschiedliche Benutzeragenten auswählen.
SCHRITT 3 - Suchmaschinen-Robots zulassen/nicht zulassen
Wählen Sie „Zulassen oder Nicht zulassen“, um die Robots-Meta-Direktiven für die angegebenen URLs festzulegen.
Sie können für jede URL separat die Anweisung „Zulassen“ oder „Nicht zulassen“ festlegen.
Warum den Robots.txt-Generator von ETTVI verwenden?
Robots.txt ist eine Datei, die verwendet wird, um dem Crawler der Suchmaschine Anweisungen zu geben, welche URLs gecrawlt oder indexiert werden können und welche nicht. Die robots.txt-Datei ist für Webmaster sehr wichtig und nützlich, und jeder SEO-Experte verwendet robots.txt für verschiedene Zwecke.
Wenn es jedoch nicht richtig geschrieben ist, kann es zu Indexierungsproblemen auf Ihrer Site führen und Google kann Ihre Website nicht richtig crawlen. Mit dem Robots.txt-Generator von ETTVI können Sie mit nur einem Klick eine genaue Datei generieren, anstatt manuell zu codieren.
Erstellen Sie schnell eine Robots.txt-Datei
Der Robots.txt-Generator kann Sie vor Codierfehlern bewahren und spart Ihnen viel Zeit, die Sie für andere SEO-Aufgaben wie die Erstellung einer Sitemap verwenden können. Die meisten SEO-Experten empfehlen den Robots.txt-Generator von ETTVI, da es sich um ein effizientes, schnelles und kostenloses Tool handelt, mit dem Sie Ihre robots.txt-Datei im Handumdrehen nach Ihren Wünschen erstellen können.
Private Seiten ausblenden
Angenommen, Sie haben eine private Seite, die Sie nur Abonnenten zeigen möchten, die aber, wenn sie indexiert wird, jeder sie sehen kann. Um dieses Problem zu vermeiden, müssen Sie Ihre privaten Seiten in der Datei robots.txt verbieten.
Crawl-Budget sparen
Wenn Sie viele zusätzliche Seiten (Like-Tags) haben, können diese Ihr Crawl-Budget beeinträchtigen und Indexierungsprobleme verursachen. Um dieses Problem zu vermeiden, verbieten wir zusätzliche Seiten in robots.txt.

Robots.txt verstehen?
Die Robots.txt-Datei ist eine Textdatei, die Informationen darüber enthält, wie ein Crawler eine Website crawlen soll. Darüber hinaus können Sie angeben, auf welche Bereiche Sie den Crawlern keinen Zugriff gewähren möchten, z. B. auf Bereiche mit doppeltem Inhalt oder solche im Aufbau. Es gibt einige Bots, die diesen Standard nicht einhalten, darunter Malware-Detektoren und E-Mail-Harvester. Daher suchen sie nach Schwachstellen in Ihrem Sicherheitssystem. Wenn Sie nicht möchten, dass bestimmte Bereiche indexiert werden, besteht eine angemessene Wahrscheinlichkeit, dass sie beginnen, Ihre Website von diesen Bereichen aus zu überprüfen.
Normalerweise gibt es zwei Robots.txt-Dateien: eine stellt den „User-Agent“ bereit und die andere enthält Anweisungen wie „Allow“, „Disallow“, „Crawl-Delay“ usw. Das manuelle Schreiben einer Datei mit Befehlszeilen kann ziemlich lange dauern und die Datei kann mehrere Befehlszeilen gleichzeitig enthalten. Sie sollten auf der folgenden Seite „Disallow: der Link, den Bots nicht besuchen sollen“ schreiben. Dieselbe Methode gilt für den Befehl „allowing“.
Warum ist Robots.txt wichtig?
Die meisten Websites benötigen keine Robots.txt-Dateien. Daher kann Google häufig alle wichtigen Seiten Ihrer Website problemlos finden und indizieren. Unwichtige Seiten oder Duplikate bereits indizierter Seiten werden nicht indiziert.
Es gibt jedoch drei Hauptgründe für die Verwendung einer robots.txt-Datei.
Erlauben Sie nicht, dass nicht öffentliche Seiten angezeigt werden. Manchmal möchten Sie nicht, dass bestimmte Seiten auf Ihrer Site indiziert werden. Sie könnten beispielsweise Staging-Versionen bestimmter Seiten oder eine Anmeldeseite haben. Es ist zwingend erforderlich, dass diese Seiten vorhanden sind, und zufällige Benutzer sollten nicht auf sie umgeleitet werden. Daher sollte die robots.txt-Datei verwendet werden, um Crawlern und Bots den Zugriff auf diese Seiten zu verwehren.
Machen Sie das Beste aus Ihrem Crawl-Budget. Wenn Sie Schwierigkeiten haben, Ihre Seiten indexieren zu lassen, liegt möglicherweise ein Problem mit dem Crawl-Budget vor. Wenn Sie robots.txt verwenden, um unwichtige Seiten zu blockieren, verbringt der Googlebot mehr Zeit mit den Webseiten, die wirklich wichtig sind.
Ressourcen sollten nicht indexiert werden. Sie können Metadirektiven verwenden, um die Indexierung einer Seite genauso effizient zu verhindern wie eine Robot.txt-Datei. Metadirektiven funktionieren jedoch nicht gut bei Multimediaressourcen wie PDFs und Bildern. In diesem Fall wäre robots.txt nützlich.
Wenn Suchmaschinen-Bots Dateien untersuchen, suchen sie zuerst nach der Datei robots.txt. Wenn diese Datei nicht gefunden wird, besteht eine erhebliche Chance, dass nicht alle Seiten Ihrer Site indexiert werden. Wenn Sie weitere Seiten hinzufügen, können Sie die Datei Robot.txt mit ein paar Anweisungen ändern, indem Sie die Hauptseite zur Disallow-Liste hinzufügen. Vermeiden Sie jedoch, die Hauptseite am Anfang der Datei zur Disallow-Liste hinzuzufügen.
Es gibt ein Budget für das Crawlen der Website von Google. Dieses Budget wird durch ein Crawling-Limit bestimmt. In der Regel verbringen Crawler eine bestimmte Zeit auf einer Website, bevor sie zur nächsten übergehen. Wenn Google jedoch feststellt, dass das Crawlen Ihrer Website Ihre Benutzer stört, wird Ihre Website langsamer gecrawlt. Da Google Ihre Website langsamer durchsucht, werden immer nur wenige Seiten Ihrer Website gleichzeitig indiziert. Daher dauert es eine Weile, bis Ihr jüngster Beitrag vollständig indiziert ist. Um dieses Problem zu beheben, muss Ihre Website über eine Sitemap und eine robots.txt-Datei verfügen. Der Crawling-Prozess wird beschleunigt, indem die Crawler auf die Links Ihrer Website geleitet werden, die besondere Aufmerksamkeit erfordern, um den Crawling-Prozess zu beschleunigen.
Zusätzlich zur Crawling-Rate für eine Website hat jeder Bot seine eigene, einzigartige Crawling-Quote. Aus diesem Grund benötigen Sie eine Robot-Datei für Ihre WordPress-Website. Dies liegt daran, dass sie eine große Anzahl von Seiten enthält, die für die Indizierung nicht erforderlich sind. Wenn Sie sich außerdem dazu entscheiden, keine robots.txt-Datei einzubinden, werden Crawler Ihre Website trotzdem indizieren. Dies ist jedoch nicht erforderlich, es sei denn, es handelt sich um ein sehr großes Blog mit vielen Seiten.
Der Zweck von Anweisungen in einer Robot.txt-Datei:
Beim Erstellen der manuellen Datei müssen Sie unbedingt wissen, wie die Datei formatiert sein muss. Nachdem Sie gelernt haben, wie es funktioniert, können Sie es außerdem ändern.
Verzögerung der Crawling-Zeit: Durch Festlegen dieser Anweisung überlasten Crawler den Server nicht, da zu viele Anfragen den Server überlasten, was nicht zu einer optimalen Benutzererfahrung führt. Verschiedene Suchmaschinen-Bots reagieren unterschiedlich auf die Anweisung „Crawl-Delay“. Beispielsweise reagieren Bing, Google und Yandex alle unterschiedlich.
Zulassen: Mit dieser Anweisung erlauben wir die Indizierung der folgenden URLs. Unabhängig von der Anzahl der URLs, die Sie zu Ihrer Liste hinzufügen, müssen Sie möglicherweise viele URLs hinzufügen, wenn Sie eine E-Commerce-Website betreiben. Wenn Sie sich für die Verwendung der Robots-Datei entscheiden, sollten Sie sie nur für die Seiten verwenden, die nicht indiziert werden sollen.
Nicht zulassen: Zu den wichtigsten Funktionen einer Robots-Datei gehört es, zu verhindern, dass Crawler auf darin enthaltene Links, Verzeichnisse usw. zugreifen können. Andere Bots können jedoch auf diese Verzeichnisse zugreifen, was bedeutet, dass sie auf Malware prüfen müssen, da sie nicht konform sind.
Unterschied zwischen einer Sitemap und einer Robot.txt-Datei
Eine Sitemap enthält wertvolle Informationen für Suchmaschinen und ist für alle Websites unverzichtbar. Sitemaps informieren Bots, wenn Ihre Website aktualisiert wird und welche Art von Inhalten Ihre Website bietet. Der Zweck der Seite besteht darin, die Suchmaschine über alle Seiten Ihrer Website zu informieren, die gecrawlt werden sollten, während der Zweck der robots.txt-Datei darin besteht, den Crawler zu benachrichtigen. Crawlern wird mithilfe von Robot.txt mitgeteilt, welche Seiten gecrawlt werden sollen und welche nicht. Damit Ihre Website indexiert werden kann, benötigen Sie eine Sitemap, während robot.txt nicht erforderlich ist.
Veelgestelde vragen
Was ist eine Robots.txt-Datei?
Advertisement
Was ist der Robots.txt-Generator?
Der Robots.txt-Generator ist ein webbasiertes Onlinetool, mit dem Webmaster benutzerdefinierte Robots.txt-Dateien entsprechend ihren Anforderungen erstellen können, ohne dass eine manuelle Codierung erforderlich ist.
Ist Robots.txt notwendig?
Nein, eine robots.txt-Datei ist nicht erforderlich, aber Sie können damit die Crawler der Suchmaschinen kontrollieren. Die meisten Experten empfehlen, eine robots.txt-Datei auf Ihrer Website zu haben.
Wie erstelle ich eine Robots.txt-Datei?
Sie können eine solche Datei mit manueller Codierung erstellen, aber das ist zu gefährlich und kann Indexierungsprobleme verursachen. Die beste Lösung, um dieses Problem zu vermeiden, ist die Verwendung eines Robots.txt-Generators wie dem von Ettvi. Mit dem Robots.txt-Generator von Ettvi können Sie kostenlos Ihre eigene benutzerdefinierte Datei erstellen.
Advertisement
Wie überprüfe ich, ob meine Robots.txt gut ist oder nicht?
Nach dem Generieren und Platzieren von Robots.txt stellt sich die wichtige Frage, wie die Robots.txt-Datei validiert werden kann. Sie können Ihre Datei problemlos mit dem Robots.txt Validator Tool von ETTVI validieren.

Blijf op de hoogte in de e-mailwereld.
Abonneer u op wekelijkse e-mails met samengestelde artikelen, handleidingen en video's om uw tactiek te verbeteren.
