What is Crawl Budget? How to Save it and Solve Indexing Problem

Qasim Agha Khan
Jan 04, 2023
Jan 04, 2023
Share this post:
Table Of Contents
Crawl budget is a general term describing how often and how many pages google crawls from a website in a given period.
If you are into SEO, you have probably heard of the term
"Crawl budget."
It is a concept that plays a critical role in determining “how search engines interact with your website.”
But what exactly is the crawl budget? And how can you manage it efficiently to improve your site's indexing?
Let's break it down in simple terms.
In a nutshell, the crawl budget is the number of pages a search engine, like Google, crawls on your site within a given timeframe.
Or simply!
“It is the attention search engines give your website.”
Search engines use bots (also known as crawlers) to find new or updated content on the web. These crawlers visit your site. And follow links from page to page to discover what’s there.
However, they don’t have unlimited resources. Google, for instance, allocates a specific amount of time and resources to crawl each site. This is your "crawl budget."
Consider it as a budget you would have for shopping. If you have a fixed amount to spend, you need to decide where to allocate it.
Similarly, search engines have a fixed amount of resources. That they can spend on crawling your website.
Moving on, let us see!
Crawl budget is very important for large websites. If Google does not crawl your pages. They would not be indexed. And if your pages are not indexed, they will not show up in search results. Right?
This can lead to missed opportunities for traffic and rankings. The crawl budget can differ depending on the search engine or crawler.
According to Google, it is not something most site owners need to be concerned about unless:
Your site has over a million unique pages. And you update content about once a week.
You manage a medium-sized site with around 10,000 pages. Plus, you update content daily.
You operate a news website that requires frequent crawling.
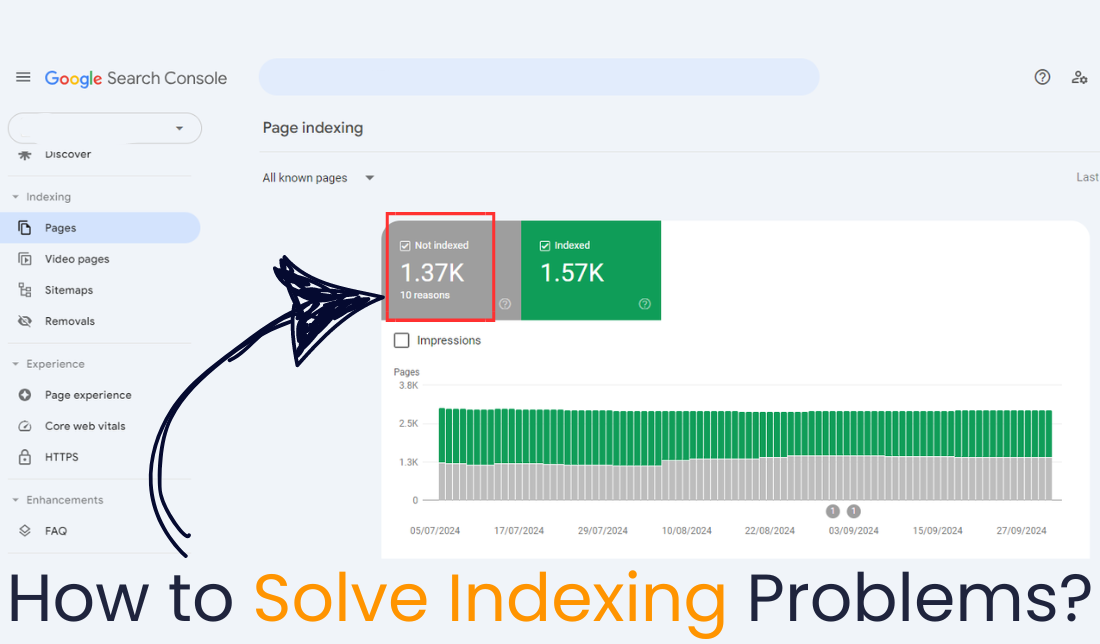
Google Search Console shows most of your URLs as "Discovered—currently not indexed."
In these situations, crawl budget management is very important.
Several factors influence your crawl budget. If you understand them, these can help you manage it more effectively. We will discuss them one by one now!
The bigger your website, the more pages there are to crawl. So, if there is a large e-commerce site with thousands of product pages. It will have more pages competing for attention from crawlers.
Faster websites are easier for search engines to crawl.
If your site takes too long to load, crawlers might give up before they can index everything. This affects the number of pages they will visit in one session.
If your site frequently updates with new content, Google may allocate more resources to crawl it more often.
Websites that are updated regularly signal to Google that there is always fresh, relevant content to check out.
How you link your pages internally plays a role too.
If your pages are well connected through internal links, crawlers can easily move from one page to another.
If your website has lots of duplicate content. You might be wasting your crawl budget. Crawlers may spend time indexing pages that do not offer anything new or valuable.
Pages with 404 errors or too many redirects can also eat up your crawl budget. Search engines may waste resources trying to crawl pages that do not exist or are hard to access.
Before you move on to save crawl budget, it is important to check the crawlability issue in your site. Go to the Ettvi’s Crawlability Checker to identify any crawling issues. It includes broken links or inaccessible pages.
Now that you have found issues in the crawlability that are wasting your crawl budget. Let’s explore some strategies to save it. Here are these!
The first step in optimizing your crawl budget is to decide:
“Which pages are most important?”
Not all pages need to be crawled frequently. Focus on your primary pages. Those that drive organic traffic or conversions.
Let us say you run an e-commerce site. Your product pages and category pages should take priority. On the other hand, old blog posts or press releases may not need to be crawled regularly.
You can use your robots.txt file to tell search engines which pages they should ignore. Use Ettvi’s Robots.txt Generator to easily create a file that instructs crawlers to spend time on your most valuable pages.
This helps ensure that crawlers spend time on the most valuable pages.
As mentioned earlier,
“Faster websites are easier for crawlers to scan.”
Use Ettvi’s Website Speed Test tool to analyze your site's performance. Just enter your domain and click "Check.”
If your site is slow, crawlers may not be able to crawl as many pages during each visit. There are several ways to improve your site speed. You can
Compress images
Minimize CSS and JavaScript files
Use a content delivery network (CDN)
Reduce server response times
If you improve your site speed, it will help save your crawl budget. And enhance the user experience. So, you can get better rankings.
Broken links and 404 errors can hurt your crawl budget. Crawlers might waste time trying to access pages that do not exist. So, there will be fewer resources for the pages that matter.
Regularly audit your site for broken links using Ettvi’s Broken Links Checker tool. Enter your domain and click the “Chech” button.
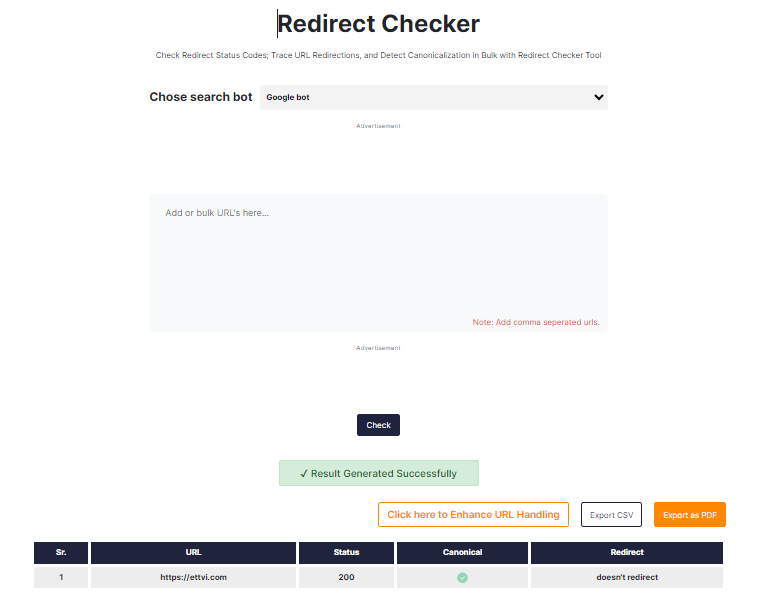
Also, minimize the number of redirects on your site. Check the redirects often to optimize them. Go to Ettvi’s Redirects Checker tool, put your domain name and click the “Check” button.
Too many redirects can slow down crawlers. It compromises their ability to quickly browse your website.
If you have duplicate content, you are wasting your crawl budget.
For example, say you have multiple pages with very similar content. Search engines may crawl and index each of them. Which is not an efficient use of resources.
You can solve this by:
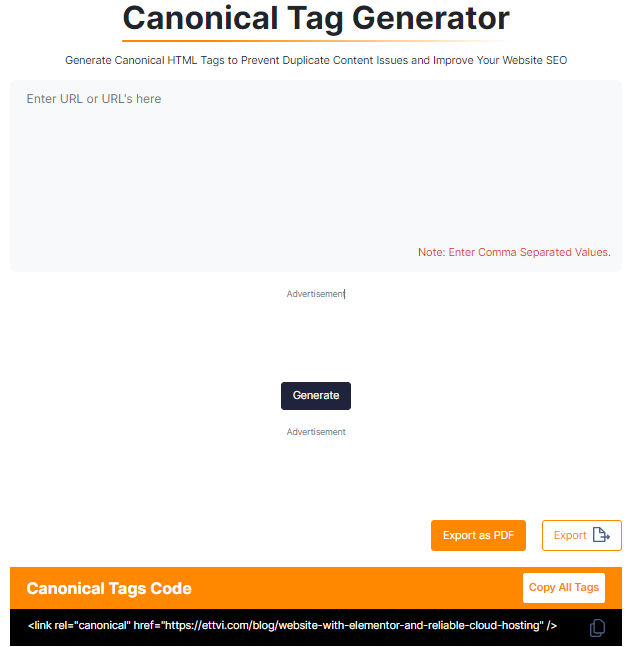
Using canonical tags to tell search engines which version of a page to prioritize. Use Ettvi’s Canonical Tag Generator to quickly create the correct canonical tags for your pages. Open the tool, paste your URL and click the “Generate” button. This will guide crawlers to the correct version of your page.
Merging duplicate pages into one.
Removing unnecessary or low-value pages that offer little to no benefit.
Pagination is often used on large websites. Especially e-commerce sites with hundreds or thousands of products. However, improper pagination can confuse search engines and waste your crawl budget.
Ensure that your pagination is clear. And it follows SEO best practices. Use
rel="next"
tag for next page and
rel="prev"
Tag for previous page. It will help search engines understand the order of your pages.
URL parameters can create multiple versions of the same page. It causes unnecessary crawling and indexing.
For example, a product page with different sorting options (e.g., ?sort=price or ?sort=name) may be treated as separate pages by search engines.
Use parameter handling in Google Search Console to tell Google how to treat these URLs. If the pages don’t offer unique content, you can prevent them from being crawled.
Indexing problems can be fixed by keeping an eye on your crawl budget. But
“What do you do if some of your important pages still are not being indexed?”
Let’s discuss how to solve common indexing problems.
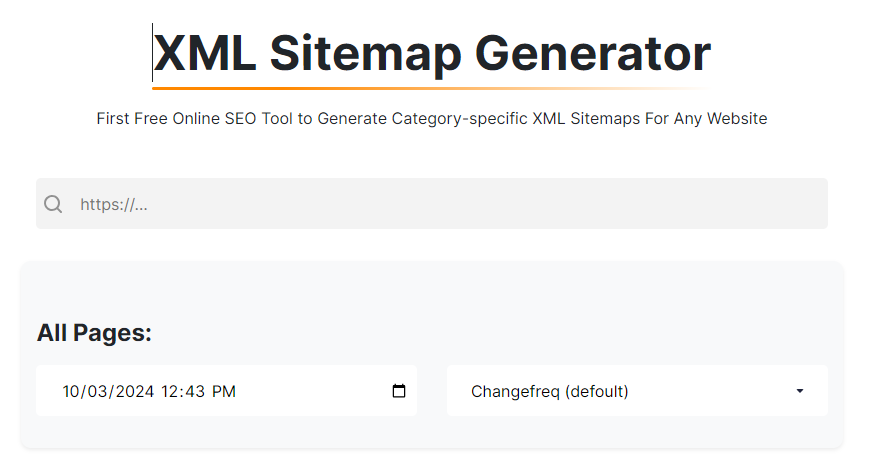
One of the simplest ways to help search engines index your site is to submit a sitemap. A sitemap is a file that lists all the important pages on your website. It simplifies for crawlers to find and index them.
Use Ettvi’s Sitemap Generator to make a sitemap.
Make sure your sitemap is up-to-date. And includes all your key pages. You can submit your sitemap through Google Search Console.
Sometimes, pages may not be indexed because they have a "noindex" tag in the HTML code. This tag tells search engines not to include the page in their index.
If you want certain pages to be indexed, ensure that there are no accidental "noindex" tags in place. This can often happen if you're using a CMS or an SEO plugin with automated settings.
Since Google is now indexing websites based on mobile devices first. It is very important that your website works well on phones.
If your site has mobile usability issues, Google may struggle to crawl and index it. You can check for mobile usability problems in Google Search Console. And fix any issues related to responsiveness, font size, or touch elements.
Orphan pages are pages on your website that aren’t linked to from anywhere else. Search engines have a hard time finding these pages since they rely on internal links to navigate your site.
Make sure that every important page on your site is linked from at least one other page. This improves the chances that crawlers will find and index them.
Finally, ensure that your content is optimized for search engines. Use clear and descriptive titles, headings, and meta descriptions.
Meta tags are a very crucial part of SEO-optimized content. Keep your content well-structured with relevant keywords. So that crawlers can easily understand what each page is about.
Not every website owner has to worry about their crawl budget. But for bigger sites, it is very important to do it right. Your site's crawl efficiency will increase and indexing issues will be resolved if you know what the crawl budget is, why it matters, and how to save it.
You can make sure that search engines use their resources wisely and keep your important pages indexed by giving your most important pages the most attention, speeding up your site, fixing bugs, and optimizing your content. Use Ettvi’s efficient tools mentioned for each point and save your crawl budget.
Jan 04, 2023
Qasim Agha Khan is a seasoned SEO consultant and digital entrepreneur with over a decade of experience helping businesses improve their online visibility and drive organic traffic. He is also the author of the bestselling book '10 Minutes SEO,' a comprehensive guide to mastering search engine optimization strategies in a concise and actionable manner.




Copyright © 2025 ETTVI | All Rights Reserved
Get in touch with our support team.