How Do You Block a Spam Domain in Robots.txt?

Umar Rashid
Nov 22, 2024
Nov 22, 2024
Share this post:
Table Of Contents
To block a spam domain in robots.txt, add: Disallow: / followed by the domain you want to block. You can read this blog to understand the process
The growing number of spam domains is a big problem for website owners. It slows down sites, messes up analytics data, and could even put security at risk. These malicious domains generate unnecessary traffic, consume valuable server resources, and often have evil intentions, such as phishing or distributing malware.
One effective way to combat these threats is by using the robots.txt file, a simple yet powerful tool for controlling web crawler behavior.
As part of the Robots Exclusion Protocol, the robots.txt file lets website owners tell automated bots which parts of their site they should not be able to access. If you set up this file correctly, spam domains will not be able to crawl and index your website, which will lessen their effect. This guide provides a comprehensive overview of what a robots.txt file is and how to block a spam domain in the robots.txt file.
Robots.txt is a simple text file that webmasters use to guide search engine robots in crawling their website pages. It tells these robots which files to access and which ones to ignore. It is also known as the Robot Exclusion Protocol.
A robots.txt file's main job is to stop too many requests from coming to your site. It may affect your search engine ranking, but its primary function is to tell search engine crawlers to focus on current and important content instead of less important content.
When search engine crawlers visit your site, they first look for a robots.txt file. This file instructs them on which content to crawl and index and which to skip. Essentially, it blocks certain content from being crawled and redirects the robots to other parts of the site.
A robots.txt file can help you keep Google from crawling private photos, old deals, or other pages you do not want people to see now. You can help your SEO by blocking a URL with robots.txt.
You can also use it to get rid of duplicate content, though there may be better ways to do this. Before a crawler looks through your site, it checks to see if there is a robots.txt file that blocks certain files.
The first thing you need to do to protect your website from unwanted and possibly harmful traffic is to identify spam domains. There are often patterns and behaviors that spam domains exhibit that can help you spot them quickly.
One common indicator is an unusually high bounce rate, which occurs when visitors leave your site almost immediately after arriving. This behavior suggests that the traffic is not genuinely interested in your content and could be generated by automated scripts or bots. You can find these spam domains early by keeping a close eye on your bounce rate.
Another sign is traffic patterns that do not seem to be normal, like sudden spikes that come from nowhere. Most of the time, these spikes are caused by automated bots or referral spam, not real people visiting. If you keep looking at your traffic data for these strange patterns, you can find spam domains.
Sometimes strange domains will show up in your referral traffic reports. This is a sign of referrer spam. Usually, these domains have no reason to link to your site, and having them there can make your analytics data less accurate. This kind of referrer spam not only messes up your data but clicking on the links in it could also put your security at risk.
User agents can also be used to find spam domains. A lot of spam bots use user-agent strings that are different from those used by real search engines and browsers. Identifying these strings in your server logs can help you pinpoint malicious traffic.
Once you have identified the spam domains, the next step is to block them using the robots.txt file. This file is an important part of the Robots Exclusion Protocol and lets you firmly manage how web crawlers interact with your website. If you set up this file correctly, spam bots will not be able to access and index your content. Follow these steps to effectively block spam domains:
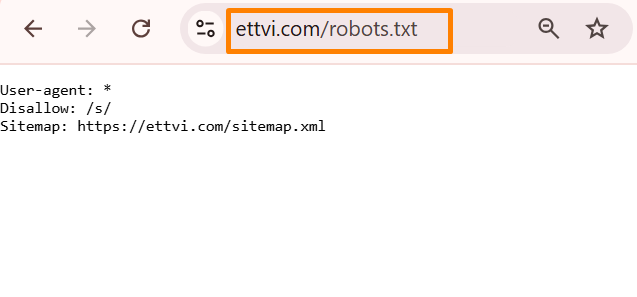
The robots.txt file is commonly located in the root directory of your website. For example, if your website is www.yourwebsite.com, the robots.txt file should be accessible at www.yourwebsite.com/robots.txt. This file must be a plain text file and not an HTML or other type of document.
If you want to change the robots.txt file, make sure you have the right permissions. You might need to use an FTP client or log in to the hosting control panel for your website to do this. If you’re using a content management system (CMS) like WordPress, there are often plugins or built-in tools that allow you to edit the robots.txt file directly from the admin panel.
The robots.txt file is an effective tool for controlling the behavior of web crawlers on your website. You can restrict the parts of your site that these bots can access by customizing specific directives. It is essential to understand the robots.txt file's syntax in order to implement effective rules. Here are the basic elements:
The user-agent directive identifies the web crawler or bot to which the following rules apply. Each search engine bot has a unique user-agent string. For example, Google's web crawler is identified as "Googlebot," while Bing's crawler is "Bingbot." By specifying a user agent, you can target rules for specific bots.
The Disallow directive prevents the specified user-agent from accessing specific pages or directories. It is an essential tool for protecting sensitive areas of your site and managing which parts of your site are indexed by search engines.
The Allow directive is optional and is used to permit access to certain pages or directories that might otherwise be blocked by a Disallow rule. This is particularly useful when you have a general disallow rule but want to make exceptions for specific resources.
Your sitemap file is an XML file that lists all of your site's URLs. The Sitemap directive tells your browser where to find it. This helps search engines better understand the structure of your website and find all its pages more efficiently. Your site will be indexed better if you put the location of your sitemap in your robots.txt file.
To block spam domains, you need to focus on the User-agent and Disallow directives. Here is an example of how to block a spam domain:
User-agent: spamBot
Disallow: /
In this case, spamBot is the user-agent of the spam domain you want to block, and / or means that this bot can not access any pages.
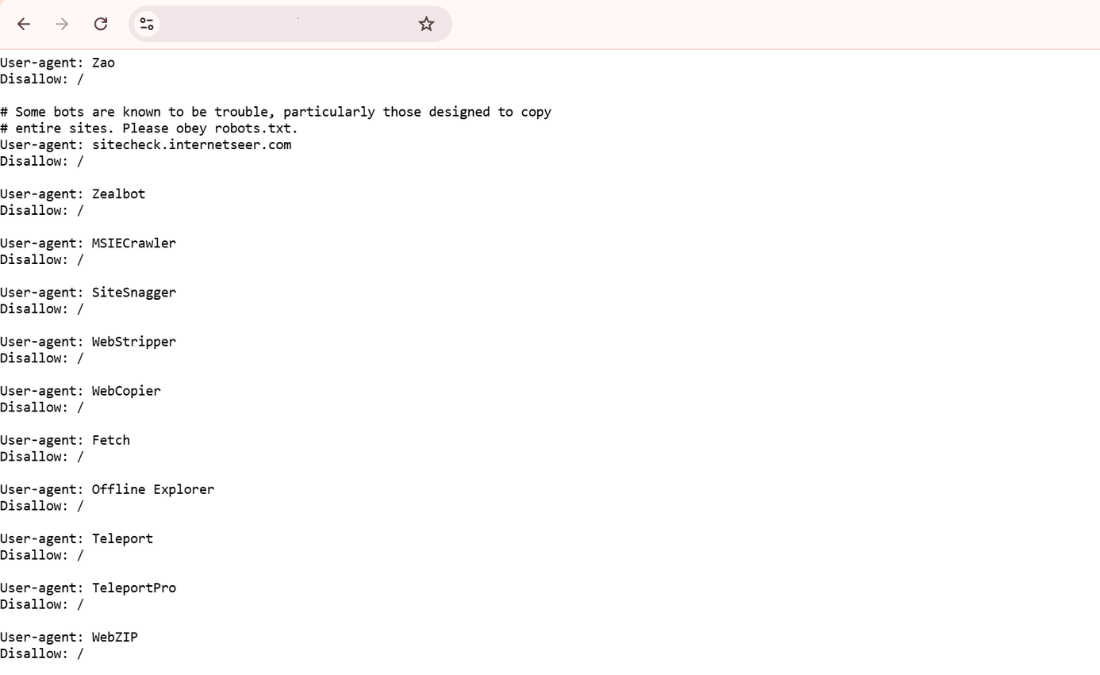
To block multiple spam domains, repeat the User-agent and Disallow directives for each bot:
User-agent: spamBot1
Disallow: /
User-agent: spamBot2
Disallow: /
User-agent: spamBot3
Disallow: /
After updating the robots.txt file, it is crucial to test and verify its correctness.
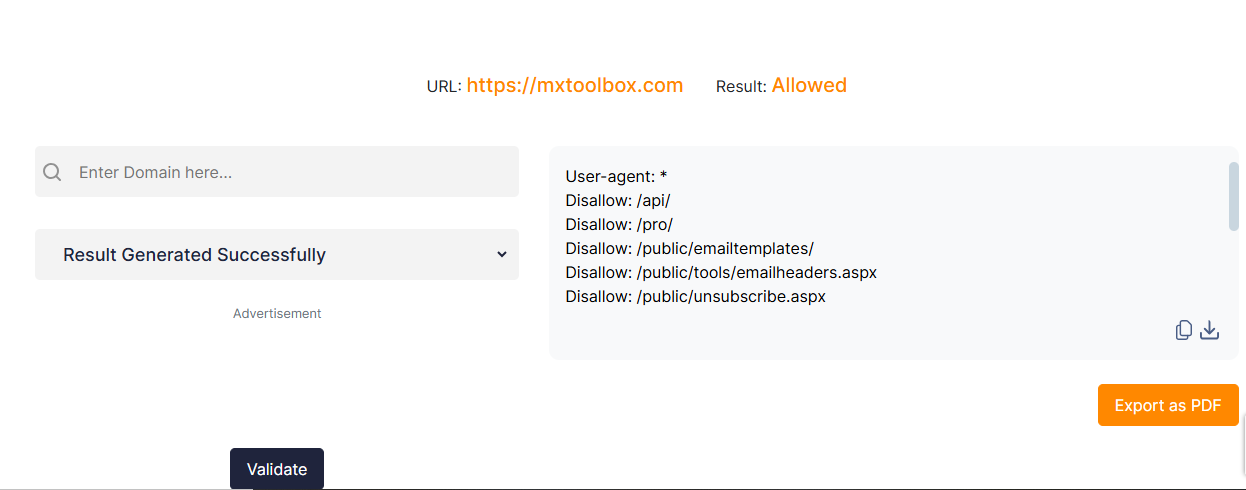
Check for syntax errors by employing online tools. Go to Ettvi’s Robots.txt Validator and enter your domain name. Then select the bot and click the “Validate” button. The tools will provide you with all the bot files with permissions.
It will help you make sure that your robots.txt file is formatted correctly and that web crawlers understand the directives correctly.
Keep an eye on your server logs and analytics to make sure that the spam domains are not still visiting your site. This can be done by checking for any accesses by the blocked user agents and verifying that the unwanted traffic patterns have decreased or stopped.
Here is an example of a complete robots.txt file that blocks multiple spam domains:
User-agent: *
Disallow: /private/
User-agent: spamBot1
Disallow: /
User-agent: spamBot2
Disallow: /
User-agent: spamBot3
Disallow: /
Sitemap: http://www.yourwebsite.com/sitemap.xml
In this example, the /private/ directory is denied access to all bots. Specific spam bots (spamBot1, spamBot2, and spamBot3) are blocked entirely and the location of the sitemap is specified for search engines.
Do you require a comprehensive platform to resolve spammy domain concerns? Ettvi is at your disposal. Ettvi.com is a comprehensive platform that offers a wide array of tools designed to optimize your website's performance, enhance its security, and improve its search engine rankings.
Among its versatile suite of services, Ettvi provides specialized tools that are essential for managing and blocking spam domains effectively. One of these tools is the Robots.txt Generator, which makes it easier to create and manage your robots.txt file and makes sure that web crawlers follow your site's rules for indexing. Ettvi 's Sitemap Generator also helps search engines properly index your site. It makes sure that all of your valuable content can be found.
If you want to make your site more resistant to spam, Ettvi has analytics tools that can help you keep an eye on traffic patterns and spot any strange behavior. With these tools, webmasters can keep their websites clean, well-organized, and safe, without having to worry about spam domains getting in the way.
It is crucial to prevent spam domains from accessing your website in order to ensure its security and functionality. If you use the robots.txt file correctly, you can control how web crawlers behave and stop them from getting in without permission. But you need to use more than just robots.txt to protect your site.
Regularly monitoring your website’s traffic and server logs will help you stay ahead of spam threats and maintain a secure online presence. By following the steps outlined in this guide, you can effectively block spam domains and protect your website from malicious activity. These best practices will not only make your website safer, but they will also make the user experience better and make sure that your analytics data is correct.
Nov 22, 2024
Umar Rashid is an SEO Expert and content writer with a passion for technology and artificial intelligence. He has been writing informational content for over 3 years and have published articles on a variety of topics, including AI, machine learning, and natural language processing, Business, Education, Finance, SEO. If you don't find him writing content, search for him in the mountains




Copyright © 2025 ETTVI | All Rights Reserved
Get in touch with our support team.