Robots.txt Validator
A Useful Technical SEO Tool to Validate Any Website's Allow and Disallow Directives
Features

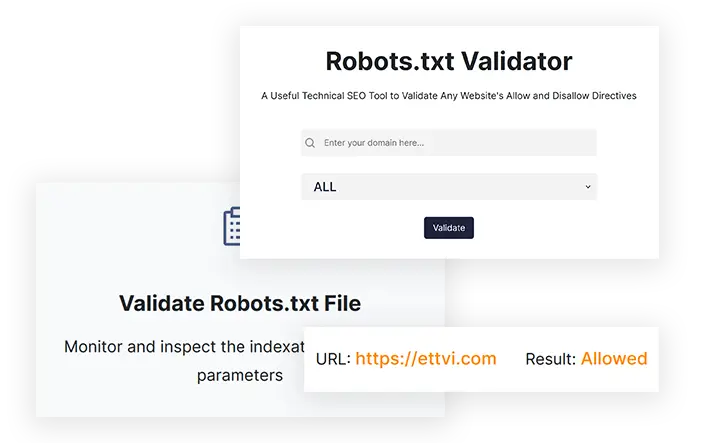
Validate Robots.txt File
Monitor and inspect the indexation-controlling parameters

Check Robots Meta Tags
Locate the URLs with the disallow and allow directives

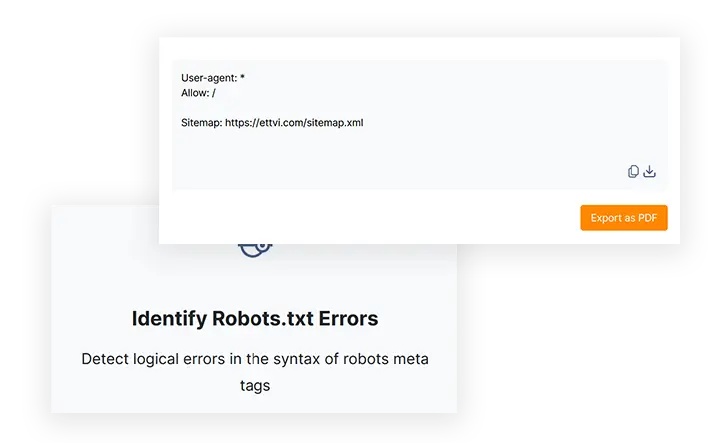
Identify Robots.txt Errors
Detect logical errors in the syntax of robots meta tags
Related Tools
ETTVI’s Robots.txt Validator
Discover the robots exclusions that prohibit the search engine from crawling or indexing your website in real-time
Make sure that all the unimportant web pages, media files, and resource files are blocked from crawling - validate the way the search engine crawlers (user agents) are instructed to crawl a website with ETTVI’s Robots.txt Validator. Enter the website URL; select the user agent, and check whether it allows or disallows the respective user agent’s activity such as crawling and indexing of a web page.
![]()
ETTVI’s Robots.txt Tester has made it easier to find out if all the crawlers are disallowed from crawling a particular page/file or is there any specific robot that can not crawl it.
Bring this useful SEO tool into service to monitor the behavior of web crawlers and regulate your website’s crawl budget - free of cost.
How to Use ETTVI’s Robots.txt Validator?
Follow these simple steps to test robots.txt file of a website with ETTVI’s advanced tool:
STEP 1 - Enter URL
Write the URL of a website as follows:
![]()
Note: Don’t forget to add “robots.txt” after the slash.
STEP 2 - Select User-Agent
Specify the crawler against which you would like to inspect the robots.txt file
You can choose any of the following user-agents:
- Google Bot
- Google Bot News
- Adsense
- AdsBot
- BingBot
- MSNBot-Media
- Yahoo!
- DuckDuckGo
- Baidu
- Yandex
- TwitterBot
- Botify
STEP 3 - Validate Robots.txt File
When you click “Check”, ETTVI’s Free Robots.txt Validator runs to identify and inspect the robots meta directives of the given website. It highlights the URLs which the selected bot can or can not crawl.
When you click “Check”, ETTVI’s Free Robots.txt Validator runs to identify and inspect the robots meta directives of the given website. It highlights the URLs which the selected bot can or can not crawl.
User-agent: * indicates that all search engine crawlers are allowed/disallowed to crawl the website
Allow: indicates that a URL can be crawled by the respective search engine crawler(s)
Disallow: indicatDisallow:es that a URL can not be crawled by the respective search engine crawler(s)
Why Use ETTVI’s Robots.txt Tester?
User-friendly Interface
All it requires you to do is just enter your website URL and then run the tool. It quickly processes the robots.txt file of the given website to track all the blocked URLs and robots meta directives. Whether you are a beginner or an expert, you can easily locate the URLs with allow/disallow directives against the selected user-agent (crawler).
Efficient SEO Tool
ETTVI’s Robots.txt Validator is a must-have tool for SEO experts. It takes only a few seconds to inspect a website’s robot.txt file against all the user agents to track logical and syntax errors which can harm the website SEO. This is the easiest way to save your crawl budget and make sure that the search engine robots don’t crawl unnecessary pages.
Free Access
ETTVI’s Robots.txt Tester lets you audit any website’s robots.txt files to sure that your website is properly crawled and indexed without charging any subscription fee.
Unlimited Usage
For a more enhanced user experience, ETTVI’s Robots.txt Checker allows you to access it and use it regardless of any limit. People from all over the world can take advantage of this advanced SEO tool to validate any website’s robots exclusion standard however and whenever they want.
Understanding Robots.txt Files
Robots.txt File is the essence of Technical SEO, mainly used to control the behavior of the search engine crawlers. Therefore, read this ultimate guide to know how Robots.txt file works and how to create it in the well-optimized way.
What is Robots.txt File?
Robots.txt file allows or disallows the crawlers from accessing and crawling the web pages. Think of Robots.txt file as an instruction manual for the search engine crawlers. It provides a set of instructions to specify which parts of the website are accessible and which are not.
More clearly, the robots.txt file enables the webmasters to control the crawlers - what to access and how. You must know that a crawler never directly lands on the site structure rather it accesses the robots.txt file of the respetive website to know which URLs are allowed to be crawled and which URLs are disallowed.
Uses of Robots.txt File
A Robots.txt file helps the webmasters to keep the web pages, media files, and resource files out of the reach of all the search engine crawlers. In simple words, it is used for keeping URLs or images, videos, audios, scripts, and style files off of the SERPs.
The majority of the SEOs tend to leverage Robots.txt file as the means to block web pages from appearing in the search engine results. However, it shouldn’t be used for this purpose as there are other ways to do it such as the application of meta robots directives and password encryption.
Keep in mind that the Robots.txt file should only be used to prevent the crawlers from overloading a website with crawling requests. Moreover, if required then the Robots.txt file can be used to save the crawl budget by blocking the web pages which are either unimportant or underdevelopment.
Benefits of Using Robots.txt File
Robots.txt file can be both an ace in the hole and a danger for your website SEO. Except for the risky possibilty that you unintetionally disallow the search engine bots from crawling your entire website, Robots.txt file always comes in handy.
Using a Robots.txt file, the webmasters can:
- Specify the location of sitemap
- Forbid the crawling of duplicate content
- Prevent certain URLs and files from appearing in SERPs
- Set the crawl delay
- Save the crawl budget
All of these practicies are considered best for the website SEO and only Robots.txt can help you to apply
Limitations on Using Robots.txt File
All the webmasters must know that in some cases, Robots Exclusion Standard probably fails to prevent the crawling of web pages. There are certain limitation on the use of Robots.txt File such as:
- Not all search engine crawlers follows the robots.txt directives
- Each crawler has its own way of understanding the robots.txt syntax
- There’s a possibility that the Googlebot can crawl a disallowed URL
Certain SEO practicies can be done in order to make sure that the blocked URLs remains hidden from all of the search engine crawlers.
Creating Robots.txt File
Have a look at these sample formats to know how you can create and modify your Robots.txt file:
User-agent: * Disallow: / indicates that every search engine crawler is prohibited from crawling all of the web pages
User-agent: * Disallow: indicates that every search engine crawler is allowed to crawl the entire website
User-agent: Googlebot Disallow: / indicates that only the Google crawler is disallowed from crawling all of the pages on the website
User-agent: * Disallow: /subfolder/ indicates that no search engine crawler can access any web page of this specific subfolder or category
You can create and modify your Robots.txt file in the same way. Just be catious about the syntax and format the Robots.txt according to the prescribed rules.
Robots.txt Syntax
Robots.txt syntax refers to the language we use to format and structure the robots.txt files. Let us provide you with information about the basic terms which make up Robots.txt Syntax.
User-agent is the search engine crawler to which you provide crawl instructions including which URLs should be crawled and which shouldn’t be.
Disallow is a robots meta directive that instructs the user-agents not to crawl the respective URL
Allow is a robots meta directive that is only applicable to Googlebot. It instructs the Google crawler that it can access, crawl, and then index a web page or subfolder.
Crawl-delay determines the time period in seconds that a crawler should wait before crawling web content. For the record, Google crawler doesn’t follow this command. Anyhow, if required then you can set the crawl rate through Google Search Console.
Sitemap specifies the location of the given website’s XML sitemap(s). Only Google, Ask, Bing, and Yahoo acknowledge this command.
Special Characters including * , / , and $ makes it easier for the crawlers to understand the directives. As the name says, each one of these characters has a special meaning:
* means that all the crawlers are allowed/disallowed to crawl the respective website . / means that the allow/disallow directive is for all web pages
Robots.txt Quick Facts
- ➔ The Robots.txt file of a subdomain is separatly created
- ➔ The name of the Robots.txt file must be saved in small letter cases as “ robots.txt “ because it is case-sensitive.
- ➔ The Robots.txt file must be placed in the top-level directory of the website
- ➔ Not all crawlers (user-agents) support the robots.txt file
- ➔ The Google crawler can find the blocked URLs from linked websites
- ➔ The Robots.txt file of every website is publiclly accessible which means that anyone can access it
PRO Tip : In case of a dire need, use other URL blocking methods such as password encryption and robots meta tags rather than robots.txt file to prevent crawling of certain web pages.

Frequently Ask Questions
Can I validate my robots.txt file against all user agents?
What is user-agent * in robots txt?
What does User Agent * Disallow mean?
Should I disable robots.txt?
Can I use ETTVI’s Robots.txt Checker for free?
What Is Googlebot’s User-Agent?
Googlebot’s user-agent is "Googlebot," which identifies Google’s crawler when accessing websites. It follows robots.txt directives to determine which pages to crawl and index, ensuring efficient search engine visibility and compliance with site rules.
Is Robots.txt Bad for My Website?
No, robots.txt helps manage search engine crawling by blocking unnecessary pages. However, improper rules can prevent indexing of important content, harming SEO. Always test robots.txt settings to ensure proper access control.
What Does Disallow Mean for Robots?
The Disallow directive in robots.txt tells search engine bots not to crawl specific pages or directories. For example, Disallow: /private/ blocks bots from accessing the "private" folder but doesn’t prevent indexing if linked elsewhere.

Stay up to date in the email world.
Subscribe for weekly emails with curated articles, guides, and videos to enhance your tactics.
